An example: “car”
Why do unigrams, bigrams and noun phrases provide different perspectives? Consider car, which can stand alone as a unigram or be part of these longer n-grams (the trigrams each include a car-related bigram). Suppose each of the car n-grams below can be found in a distinct sentence of text. Then the count of each type are as follows:
| type |
ngram |
n |
| unigram |
car |
17 |
| bigram |
car door, car electronics, car destroyed, car software, car computer, car insurance, car lcd, car navigational, car repair, car train |
10 |
| trigram |
car computer system, car insurance policy, car lcd display, car navigational system, car repair shop, car train collision |
6 |
Unigrams are less precise than bigrams and trigrams, however unigrams are helpful in signaling a general topic and occur at much greater frequency than bigrams and trigrams in the same corpus.
I find the n-grams in two ways:
Naively: simply count the occurrence of each n-gram by treating words in their base form (“lemma”) as a unigram or bigram; and
With awareness of grammatical structure to identify noun phrases.
The results of the two approaches differ considerably, primarily because with noun phrases, a subset of a larger noun phrase is not counted as a shorter n-gram.
| type |
ngram |
n |
| unigram |
car |
17 |
| noun phrase unigram |
car |
1 |
| bigram |
car door, car electronics, car destroyed, car software, car computer, car insurance, car lcd, car navigational, car repair, car train |
10 |
| noun phrase bigram |
car door, car electronics, car destroyed, car software |
4 |
| trigram |
car computer system, car insurance policy, car lcd display, car navigational system, car repair shop, car train collision |
6 |
| noun phrase trigram |
car computer system, car insurance policy, car lcd display, car navigational system, car repair shop, car train collision |
6 |
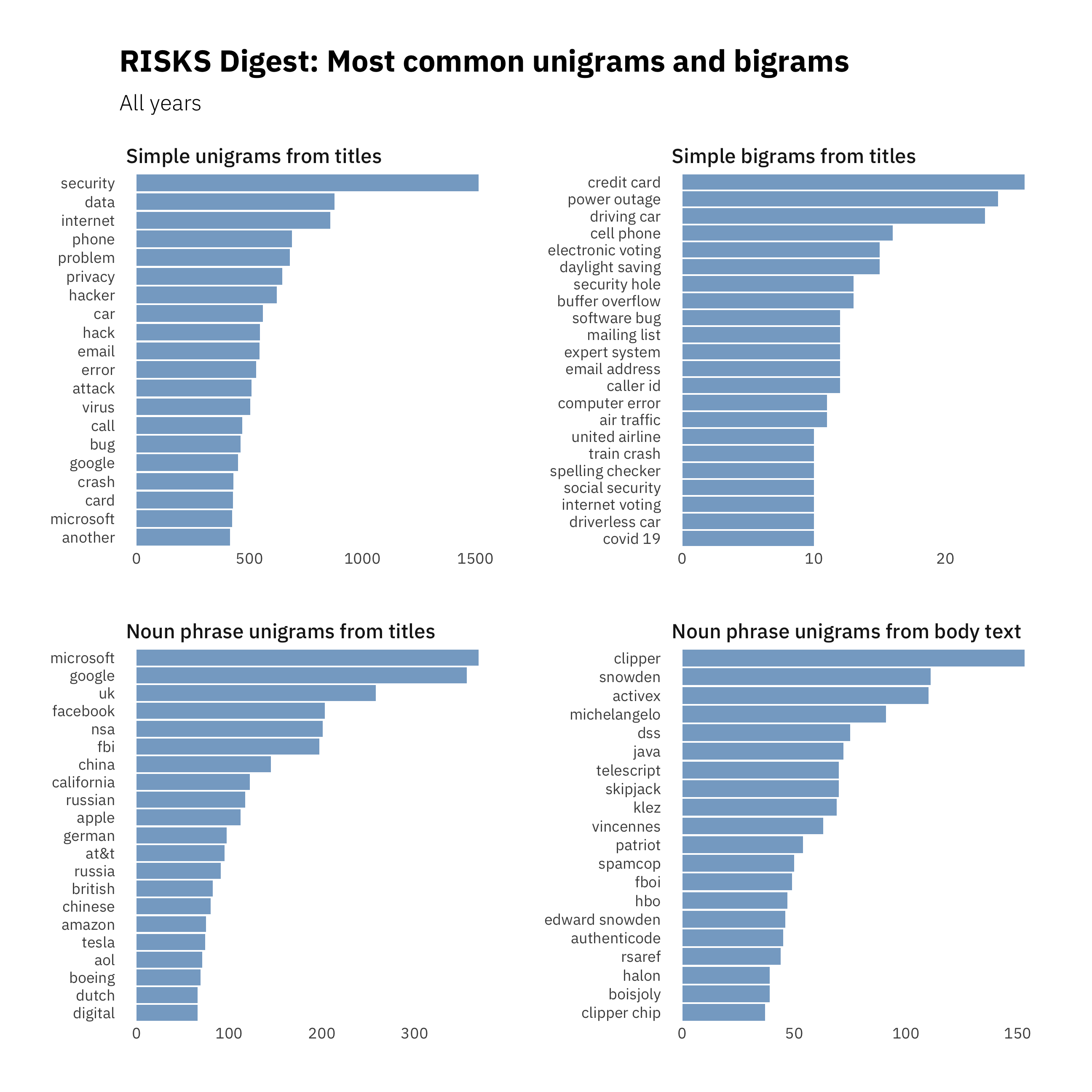
Unigrams from titles
The Visualizations and discussion in The lens uses lemmatized words as unigrams. Below we’ll look at unigrams derrived from noun phrases, which provide a different perspective.
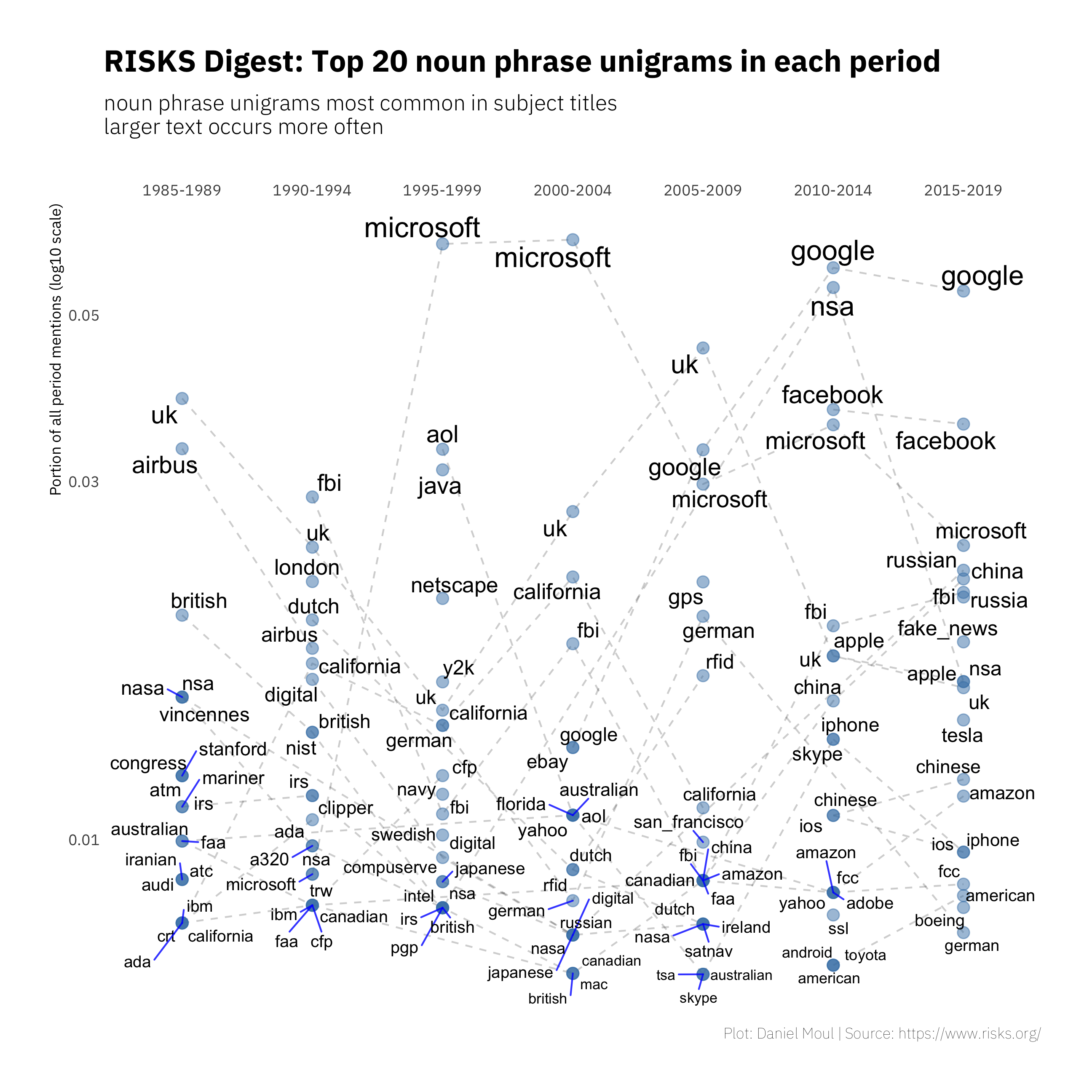
Counting the frequency of noun phrase unigrams in five-year periods and calculating a percentage of all mentions in each period makes visible some trends.
Common topics
- Aerospace has been a common source of topics, with references to manufacturers Airbus and Boeing as well as specific planes (A320, A380), rockets (Ariane), and topics related to space exploration (NASA, Mariner, mars).
- Whereas privacy, encryption and data are consistently in the top-five in the ranking of simple unigrams we looked at earlier, here they are missing. Instead the list includes many more place-related terms: British, Dutch, German, Japanese, Russia and Russian, China and Chinese, Canadian, American, California, San Francisco, etc. We also see more organizations: congress, IRS, Stanford, Intel, Amazon, Skype, NSA, and the same technology companies: Microsoft, Facebook, Google, and Apple.
Compare this to Figure 1.3
Unigrams from body text
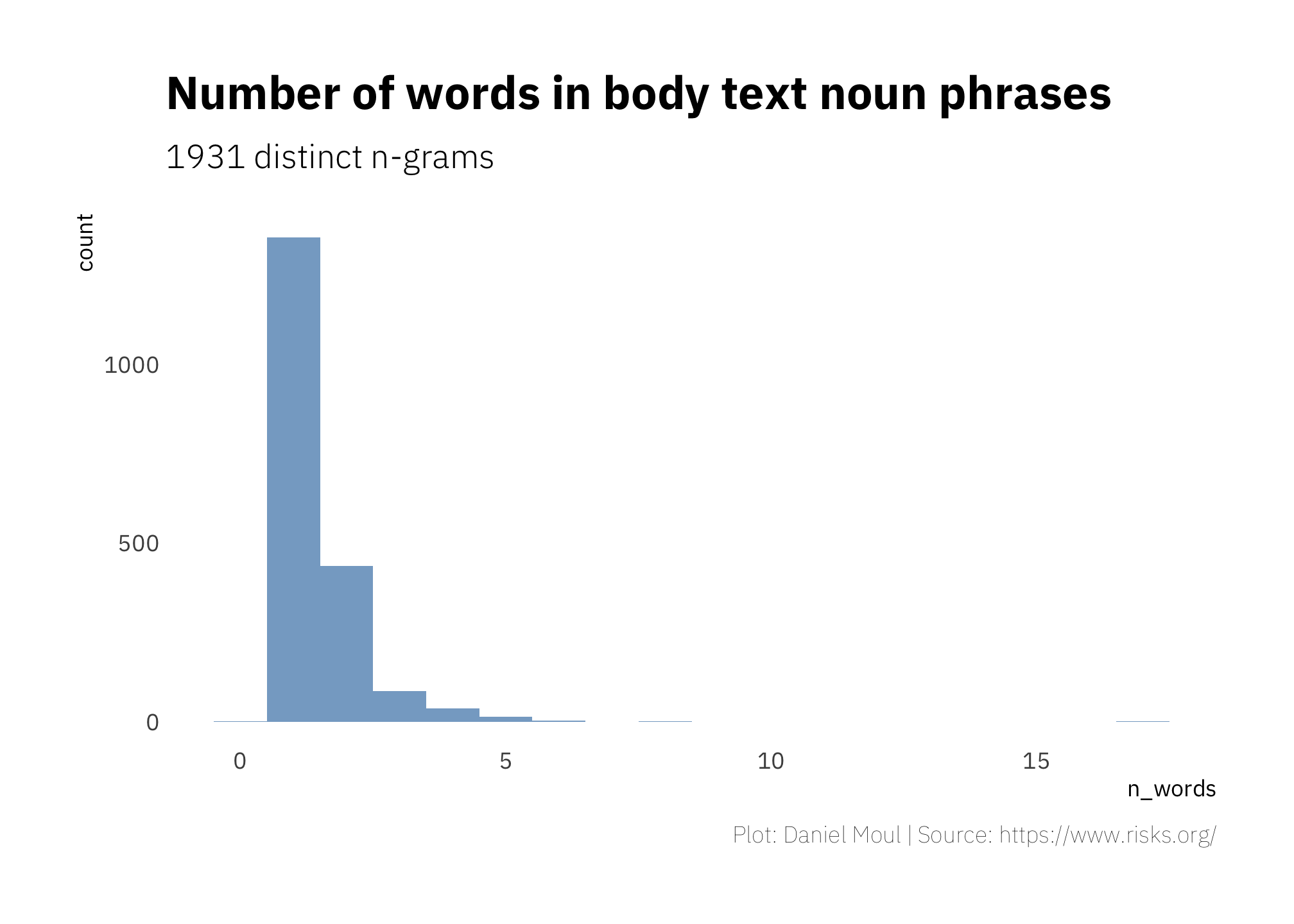
There is a lot more body text than title text: 22 times more. However, noun phrase unigrams do not include words that are not part of noun phrases or are part of multi-word noun phrases, so the set of words we have to work with is only about one tenth as large: (1,355 unique, noun phrase unigrams) compared to (15,971 unique, simple unigrams. In the body text, the most common noun phrase is one word in length, as seen in Figure 2.3:
Below are the most frequent noun phrase n-grams for each value of \(n\) in the submission body text. The 8-word n-gram is part of a frequent contributor’s email signature (“uunet!…”).
| Number of words |
Most popular n-gram |
| 1 |
clipper |
| 2 |
edward snowden |
| 3 |
michel e. kabay |
| 4 |
natl computer security assn |
| 5 |
sei conference on risk management |
| 6 |
sei customer relations software engineering institute |
| 8 |
u of toronto zoology uunet!attcan!utzoo!henry |
| 17 |
software reliability software safety computer security formal methods tools process models real-time systems networks embedded systems |
The 17-word ngram is most of a table in a call for papers for COMPASS ’94 in Volume 15 Issue 34, which after text processing, reads as follows:
Papers, panel session proposals, tutorial proposals, and tools fair proposals are
solicited in the following areas:
Software Reliability Software Safety Computer Security
Formal Methods Tools Process Models
Real-Time Systems Networks Embedded Systems
V&V Practices Certification Standards
Looking at relative frequency of the noun phrase unigrams from body text within each time period in Figure 2.4, we can see the track of technological evolution: uucp, arpanet, and clipper in the early years, followed by java, javascript and pgp in the middle years, then siri, bitcoin, iphone and android in the later years. USB shows up in the last three five-year periods.
Compare this figure to Figure 1.3 and 2.2
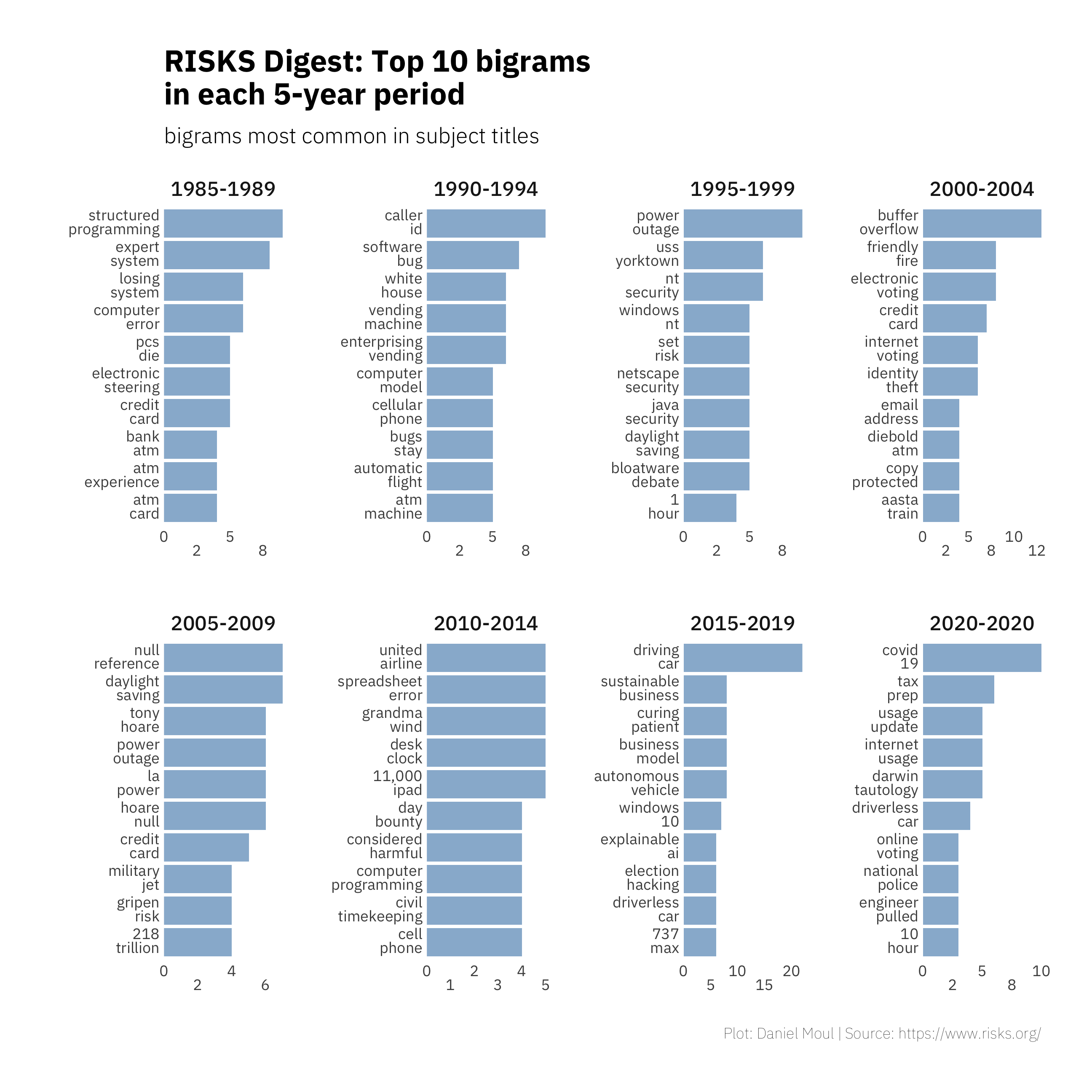
Bigrams
Bigrams are two words that occur adjacent to each other in the text. Figure 2.5 show the most common simple bigrams in each 5-year period. These are derived from the submission titles. Note the very low number of occurrences.
“Grandma wind” is third bigram in the 2010-2014 column. It illustrates some of the challenges and limitations in doing this kind of textual analysis. It’s part of the title of the thread “Don’t throw away Grandma’s wind-up desk clock” started by Danny Burstein in Volume 26.
- Grandma’s was lemmatized to “grandma”
- wind-up was separated into two words
- up was filtered out, because it’s a short, common word
- So we have grandma wind as our bigram
Figure 2.6 presents the same visualization using noun phrase bigrams from titles. Note the similarly low frequencies.
Here again we can see limitations: AT&T and fighter planes F15, F-16, and F22 should not be considered bigrams.
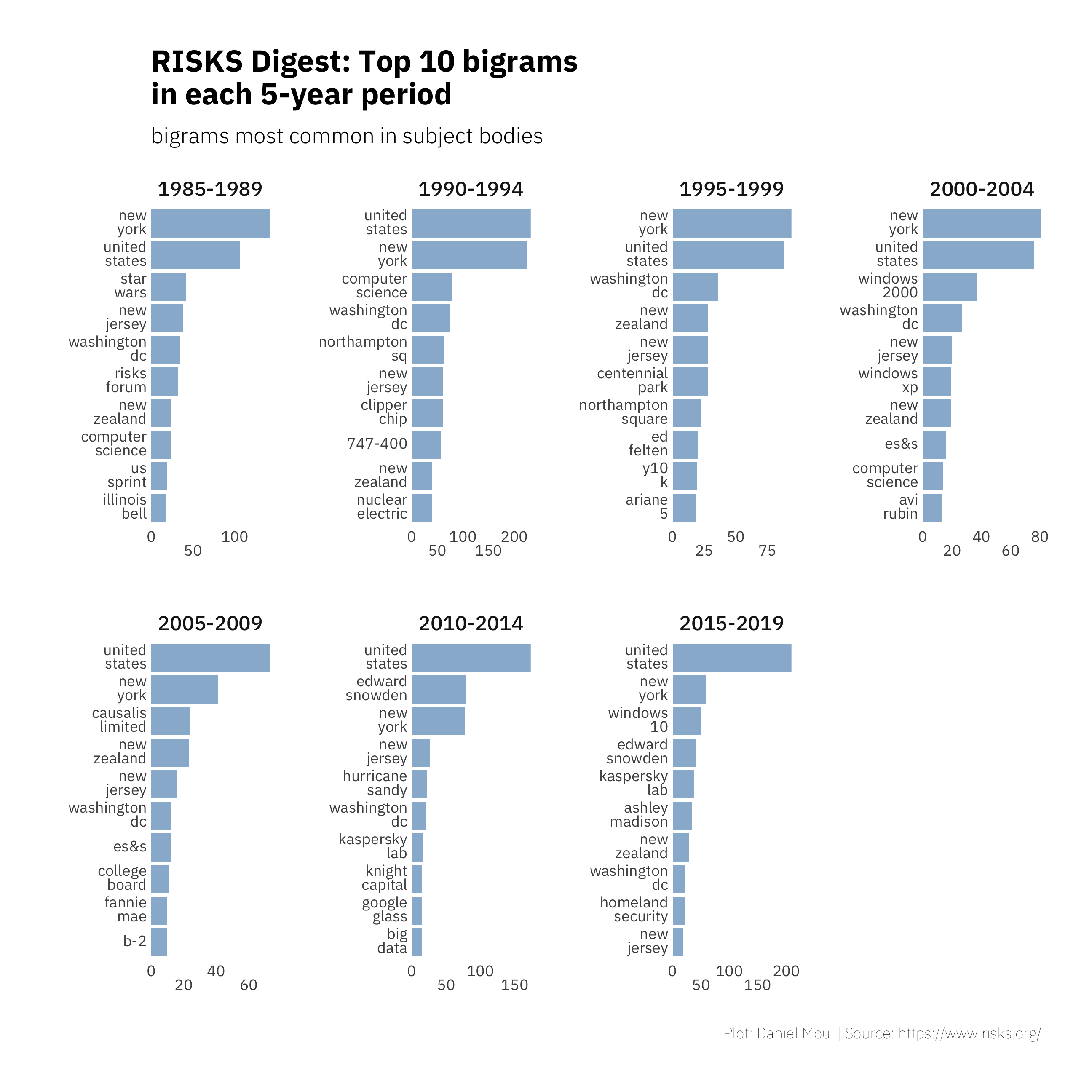
The most common bigrams sourced from bodytext noun phrases are shown in 2.7. Again place-related bigrams dominate the top of the list. This could be due in part to these bigrams being part of email signatures that I imperfectly filtered out. Further down the list we do see n-grams that we otherwise might miss, including college board, Fannie Mae, B-2, Kapersky Lab, Ashley Madison, and Homeland Security.
There is no one “correct” way to collect n-grams from a corpus. Using multiple techniques provides a richer view into the topics that have been addressed in the RISKS Forum.
By Daniel Moul (heydanielmoul via gmail)
 This work is licensed under a Creative Commons Attribution 4.0 International License
This work is licensed under a Creative Commons Attribution 4.0 International License